

August 2020 – Volume 24, Number 2
Yingying Liu
The Pennsylvania State University
<yzl222![]() psu.edu>
psu.edu>
Kevin McManus
The Pennsylvania State University
<kmcmanus![]() psu.edu>
psu.edu>
Abstract
Recent second language acquisition research has demonstrated that language learning is in essence the learning of constructions, or form-meaning pairings. Compared to first language acquisition research, however, our understanding of how constructions in a second language (L2) emerge and develop with proficiency and/or experience is limited. Furthermore, within this developing evidence base of L2 research, investigations have predominantly focused on verb-based constructions (e.g., verb-argument constructions), understood to be a core construction category of sentences. As a result, a large part of L2 speakers’ construction inventories remains to be investigated. To address this gap, a corpus-based investigation of the “article + adjective + noun” (AAN) construction in a written corpus of Chinese-speaking learners of English was carried out. Analyses show growth in construction types and developmental changes of adjectives in AANs with increasing amounts of L2 experience, consistent with usage-based understandings of language. Theoretical and pedagogical implications are discussed, including the extent to which previous findings for verb-based constructions apply to AAN constructions.
Keywords: Constructions, Learner Corpus, Writing, English as a Foreign Language
Corpus-based investigations and psycholinguistic experiments have repeatedly shown the importance of constructions, or form-function mappings, in language learning (Goldberg, 1995, 2006; Ellis et al., 2014; Ellis et al., 2016). Studies of first language (L1) and second language (L2) constructions equally support the “psychological reality” of constructions (Bencini & Goldberg, 2000; Gries & Wulff, 2005), the role of prototypes (Römer, 2009; Ellis et al., 2016), and lexeme-grammatical structure mappings (Stefanowitsch & Gries, 2003). However, compared to constructionist theoretical research and L1 acquisition research, there is much less research on L2 acquisition of constructions. Our understanding of how L2 constructions emerge and develop with proficiency and/or experience is therefore limited. Moreover, previous research has predominantly examined verb-based constructions (Römer, 2009; Ellis et al., 2016), while other types of constructions remain to be investigated.
This study examines the use of nominal constructions among Chinese-speaking learners of English. Drawing on the Ten-thousand English Compositions of Chinese Learners Corpus (Xue, 2015), we investigated the “article + adjective + noun” (AAN) construction (e.g., the-ARTICLE blue-ADJECTIVE car-NOUN) in this corpus. Previous research has documented the AAN construction as a “modifier-head construction” (Fillmore et al., 2012) and as an “attributive modification construction” (Goldberg, 2019, p.3). It is also included in the corpus-based grammar pattern list compiled by Francis, Hunston and Manning (1998). Investigating usage patterns of the AAN construction has the potential to advance understanding of the role of constructions in L2 development. Following Ellis et al.’s (2016) study of verb-argument constructions (VACs), our analyses include frequency analysis and semantic analysis, complemented with a developmental analysis of early-learned adjectives in AAN.
Literature Review
Constructions and Patterns
The term ‘construction’ refers to linguistic items of varying length (morphemes, e.g., -s, single words, e.g., apples, multi-word units, e.g., in addition to, etc.), varying complexity (bare nouns, e.g., institutions, complex nominals, e.g., an academic institution, etc.) and abstraction (fully-lexicalized idioms, e.g., let alone; abstract syntactic patterns, e.g., verb locative construction, etc.). A speaker’s language system is consequently understood to be a structured, hierarchical inventory of constructions. Goldberg (2006, p.5) defined a construction in two ways. First, as a form-meaning pairing of which the meaning of a unit is not fully predictable from its individual parts. For example, the collective meaning of kick the bucket, used when somebody dies, is different from a literal sum of meaning of the individual words (kick, the, and bucket). Second, even if a construction category is semantically fully predictable, the constructional category can still be established as long as it occurs frequently enough.
Recent research (Ellis et al., 2016; Hunston & Su, 2019; Patten & Perek, in press) has proposed a grammar pattern-based approach to identifying constructions, arguing that “each of the meaning–pattern combinations identified in Francis et al. (1996, 1998) can be regarded as a construction” (Hunston & Su, 2019, p.567). In this approach, the identification of constructions starts from retrieval of patterns in a corpus, followed by semantic analysis either manually (Hunston & Su, 2019) or semi-automatically (Ellis et al., 2016; Patten & Perek, in press). For example, Hunston and Su (2019) examined the semantics of adjectives in “it v-link ADJ that” (e.g., It is awful that it should end like this) pattern and found the majority of adjectives to be semantically related with evaluation. Consequently, the pairing of this grammar pattern and evaluative meaning was regarded as one construction category: the “evaluative it” construction. While this example illustrates a one-to-one correspondence between grammar patterns and constructions, many cases were one-to-many correspondences. In the same study, their analytical process also led to the identification of two constructions from the “ADJ at” pattern: the “reactive at” construction (e.g., she is angry at the cat) and the “(un)skilled at” construction (she is adept at baking).
Grammar patterns can provide a reliable reference for the identification of mid-level constructions (neither as general as verb locative construction, nor as specific as let alone) for three reasons: (i) in comparison to the oftentimes anecdotal identification of constructions, grammar patterns have grown out of a more systematic and thorough corpus investigation; (ii) the representation notation of grammar patterns clearly shows the fixed and optional components of construction forms; and (iii) semantic groupings of key slot-occupants in grammar patterns were based on expert interpretations of authentic corpus instances, and such sub-constructional semantic information can facilitate the construction-level semantic analyses.
Constructions in L2 Learning
Present findings of L2 construction development appear to be largely consistent with those found for L1 development, including growth in construction variety and productivity (Eskildsen, 2009; Römer, 2019), movement from more fixed sequences to flexible constructions (Li et al., 2014; Römer, 2019) and from semantically general, high-frequency words to more specific, lower-frequency words in specific constructions (Ellis & Ferreira-Junior, 2009b). Despite the valuable insights these studies offer to L2 development, the scope of this research is limited. To date, only a small number of construction types have been examined, including, for example, negation constructions, constructions of modal verbs and verb-argument constructions. Further investigation to other types of constructions with a different group of learners is therefore needed to understand the nature and function of constructions in L2 learning. Considering that learners’ L1 background may impact L2 construction development (Eskildsen et al., 2015), L1 should be a consideration in L2 construction research.
Frequency, Prototypicality and Contingency in Constructionist Research
Usage-based constructionist research has identified several determinants that contribute to the learning of constructions, including frequency, semantic prototypicality and contingency of words and constructions (Ellis & Ferreira-Junior, 2009a; Ellis et al., 2015; Ellis et al., 2016). Frequency is understood to play a particularly important role in learning. The more frequently we experience something, the more likely we will learn it (Ellis et al., 2015). Research has shown that the frequency distribution of constructions and their slot-occupants are Zipfian (O’Donnell & Ellis, 2010; Ellis et al., 2016). Zipf’s law (Zipf, 1935) states that the frequency (f) of the i-th most common word is proportional to the inverse of its frequency rank () (see Ellis et al., 2016, p.57). Applied to constructions, a Zipfian distribution entails that the most frequent slot occupant in a construction is used about twice as often as the second most frequent slot occupant in that construction, and three times as often as the third most frequent most frequent slot occupant in that construction. Research examining VACs (Ellis & Ferreira-Junior, 2009b; Ellis et al., 2016) has repeatedly shown near-Zipfian distribution of their verb-slot-occupants. For example, Römer, O’Donnell and Ellis’ (2015) analysis of the construction “Verb across N” (e.g., she came across an interesting story) showed a near Zipfian distribution because the verb slot was occupied overwhelmingly by several verbs: come (628), walk (243), and run (202). They also noted that the lead verb come is prototypical to that construction. This conclusion is important for constructionist approaches to L2 learning because a prototype is a central, ideal member of a category that best represents the typical attributes of this category (Taylor, 2003). Indeed, a number of studies have validated the role of prototypes in construction learning. Ellis, Römer and O’Donnell’s (2016) analyses of VACs in the British National Corpus (BNC) and psycholinguistic experiments, for instance, showed that the verbs that came to mind first for L1 and L2 users to fill into the VAC frames were also those central in the semantic network of verbs. These verbs were considered prototypical of the construction. Taken together, just as prototypes are understood to play a major role in L1 and L2 learning (with prototypes being learned before non-prototypes), these findings indicate that prototypes likely facilitate the learnability of constructions (Goldberg et al., 2004; Goldberg, 2006).
Another semantic factor understood to underpin the learnability of constructions is the semantic genericity of words. Semantically general words are understood to be learned earlier (Goldberg, 2006; Ellis & Ferreira-Junior, 2009a; Ellis et al., 2015). For example, Ellis & Ferreira-Junior (2009a) found that L2 learners used the verb go in verb locative construction from an early stage of acquisition. This verb continued to be used most frequently in this construction, despite other verbs (e.g., walk, move, run, travel) surpassing this word in semantic prototypicality. They proposed that this observation can be explained by a higher degree of semantic genericity of go.
Contingency indicates how reliable the mapping is between the cue and the outcome (i.e., how often the same word leads to the same interpretation). The association of words and constructions can be interpreted from the perspective of contingency. Higher contingency words (i.e., words that reliably index the same meaning) should be more readily learned and thereafter more readily associated with the construction in language processing. Ellis (2006) introduced a one-way dependency statistic (ΔP) to the analysis of word-construction contingency. Both word-to-construction ΔP and construction-to-word ΔP are found to be strong predictors for construction learning (Ellis & Ferreira-Junior, 2009b). Research on L2 acquisition of constructions tends to first obtain measures of frequency, semantic prototypicality and contingency from L1 data and then examine their effects on L2 development. While such an approach indicates relational properties of constructions that likely influence L2 development, other factors in L2 development were not sufficiently examined, such as L2 proficiency and grade level.
Zooming in on the Adjectival Slot in AAN
When examining the lexis-grammar interface of constructions, research has tended to focus the frequency analysis on the most varying and characteristic slot of the target constructions (Ellis et al., 2016; Hunston & Su, 2019). For example, Ellis et al. (2016) analyzed the frequency distribution of the verb-slot fillers for VACs, given that noun components were semantically unrestricted. In our examination of AAN, constructional restrictions are mainly restricted to the adjectival slots. As noted by Goldberg (2019, p.3), adjectives initiated with a cannot be used in AAN for etymological reasons. The adjectival slot in AAN therefore should receive most attention in this analysis. In addition, given the semantic property of AAN, either very general (Goldberg, 2016) or even meaningless (Fillmore et al., 2012), the focus of semantic analysis should be at the lexeme-construction interface rather than the constructional meaning.
Current study
The present study investigated “article + adjective + noun” (AAN) constructions in a learner corpus of L2 English writing. Our research design addresses the previously identified gap in two important ways. First, since previous research has mostly examined constructions in verb-based structures (e.g., VACs), the current study extends this focus to include nominal constructions. Second, we examine the L2 development of constructions and the extent to which usage might be influenced by increasing amounts of exposure to and/or experience with English by investigating L2 learners at three broad grade levels (elementary school, middle/high school, university).
Addressing the above gaps in previous research has the potential to advance knowledge and understanding about the role and nature of constructions in L2 learning. Specifically, the current study sought to address the following research questions:
- To what extent do learners’ AAN repertoires differ across grade levels?
- To what extent does the semantic distribution of adjectives in AAN constructions change across grade levels?
- What are the first AAN adjectives acquired by Chinese learners of English?
- To what extent does the frequency ratio, contingency and dispersion of adjectives in AAN constructions vary as a function of grade level?
Corpus
The corpus data used in the present paper was from Ten-thousand English Compositions of Chinese Learners Corpus (TECCL; Xue, 2015), which contains 9864 essays produced by Chinese EFL learners from elementary school to university. The corpus consists of narrative and argumentative essays electronically submitted to an online writing and scoring system from 2011 to 2015. The texts include both in-class and out-of-class assignments. Importantly, the online platform did not provide corrective feedback to students during the writing process. As a result, the collected essays have no outside edits and represent the students’ independent writing abilities. 138 essays in TECCL were excluded from our analysis because the education institution level of the author was unspecified, and the remaining dataset for this study included 9726 texts, totaling approximately 1.7 million words. Table 1 summarizes the composition of our dataset.
To address the potential influence of topic variability on constructional diversity, a subset of writings on the same topic (see Appendix) were analyzed to understand constructional diversity. Other analyses, such as semantic analysis of adjectives, intra-group distribution and developmental analysis of shared adjectives, used the full corpus without controlling for topic in order to increase the representativeness of this corpus for understanding AAN use by Chinese EFL learners.
Table 1. Composition of Dataset in this Study.
| Measure | Elementary school | Middle/High school | University |
| number of texts | 58 | 2,801 | 6,867 |
| number of words | 5,446 | 370,710 | 1,327,173 |
The part-of-speech tagged corpus (with CLAWS C7 tagset) was used in our analysis. Based on three file name lists (one for each grade level) retrieved from the “TECCL_V1.1_list_of_texts” table on the corpus website, a Python script was used to divide the TECCL corpus into three sub-corpora by the education institution level of the students: the elementary school dataset (EL), the middle/high school dataset (MS), and the university dataset (UN). This allowed us to examine L2 learners’ use of AAN constructions at three broad grade levels.
Corpus Data Extraction
We limited our definition of AAN to word sequences that included all three substantiated slots (article followed by adjective followed by noun, e.g., the blue car), and excluded patterns with null articles (e.g., green cars) and patterns with possessive determiners in the article slot (e.g., my green car). This is because (i) considerable L2 acquisition research has investigated bigram adjective-noun collocations (Siyanova & Schmitt, 2008), and (ii) the “possessive determiner + adjective + noun” pattern deserves a separate investigation in future research. Therefore, the target AAN construction in this paper is the form-meaning pairing of the “article + adjective + noun” pattern and its referential function.
All instances of AAN patterns were first retrieved from each of the three datasets using the AntConc program (Anthony, 2018) through a regex search pattern:
_AT.? [A-Za-z]*_(JJ|MD|DA.?) [A-Za-z]*_NN.?
The C7 Tagset provides two separate tags for the definite and indefinite articles, that is, AT for definite articles and AT1 for indefinite articles. This regex pattern ensures that both definite and indefinite article tags are included. The regex pattern also includes ordinal attributives like first, second (tagged as MD) and after-determiners (tagged as DA, particularly same) as legitimate adjective-slot-fillers in addition to adjectives with the JJ tag. The inclusion of these words into the adjective category is consistent with several English dictionaries. For example, the ordinal attributives and the word same were regarded as adjectives in the Merriam-Webster’s Advanced Learner’s English Dictionary (Merriam-Webster, 2008) and the Longman Dictionary of Contemporary English (Pearson Education, 2003).
Analyses
Four types of analysis were conducted. The first two analyses were conducted to answer the first research question on the development of AAN repertoires, with diversity analyses examining changes in AAN types and frequency distribution analyses examining the distributions and changes of adjectives. The semantic analysis responds to the second research question by analyzing the semantic groupings of adjectives in AANs and their changes across grade levels. To address the third and fourth research questions, the developmental analysis of first-learned adjectives in AAN constructions presents a visualization of adjective-construction associations across grade levels.
Diversity analysis. Type frequency of adjectives and instantiated constructions (the number of different forms) was used to measure construction diversity. If a search returned the following instances, the black cat, the yellow cab, the black cat, AAN type frequency would be two (because there are two different forms of the same construction) in this case. Since the sub-corpora varied in size, normalized type frequencies were used for cross-sectional comparison. In addition, we subsampled and analyzed texts concerning the same topic of “school/university” (see Appendix), considering possible impacts of topic variability on construction diversity.
Frequency distribution analysis. Token frequency and (token) frequency rank of adjectives were computed in Microsoft Excel using the lists of retrieved AAN instances. Then, according to the adjusted formula for Zipf’s law adopted in Ellis, Römer & O’Donnell (2016, p.58), two variables were computed in Excel: logarithmic token frequency and logarithmic adjusted frequency rank (i.e., the logarithm of the sum of token frequency rank and the numeric value of 2.7). A linear regression analysis between the two variables was run in R (Ihaka & Gentleman, 1996) to examine if the type-token distribution of adjectives in AAN constructions follows Zipf’s law. If the coefficient of determination (denoted by R2, which is a measure of goodness of fit) was .50 or above (understood to indicate a high goodness of fit, see Plonsky & Ghanbar, 2018) and the slope was around -1 (Römer et al., 2015), the distribution was considered to be near-Zipfian.
Semantic analysis of adjectives in AANs. Biber et al. (1999, p.508ff; see also Biber & Gray, 2016) proposed a taxonomy of semantic functions of adjectives as nominal pre-modifiers, consisting of two major semantic functions: descriptive and classifying. The descriptive function further comprises two subcategories: descriptors for physical characteristics (e.g., a red apple, a large number) and descriptors for evaluations (e.g., a good way, a beautiful cat). The classifying function also has two subtypes: relational classifiers for making comparisons with other referents (e.g., the same person, a different method) and topical classifiers that identify the type or subject area of the noun (e.g., the statistical approach, a qualitative appraisal). We coded all retrieved instances of AAN (n = 30,059) with the four above-mentioned semantic categories (i.e., descriptive-physical, descriptive-evaluative, classifying-relational, classifying-topical) and an extra category of ordinals (e.g., first, second). Learner errors (e.g., the aboved factors, a complete college) and tagging errors (e.g., the Baoding City where Baoding is the pinyin of the city name in Mandarin Chinese) were also identified manually. Table 2 presents the current coding scheme and the reference schemes. Twenty-five percent of these instances (7,515 instances) were independently annotated by the first author and another expert user of English. Interrater reliability before comparisons was 79.4% (Cohen’s kappa κ = .71). The coders then discussed each difference before using an agreed semantic annotation. The first author then annotated the remaining instances using the agreed semantic annotation.
The majority of instances were annotated with only one semantic tag, except for a small number of borderline cases that included two tags (0 token in EL, 7 tokens in MS, 94 tokens in UN). For instance, the basic factor, a fundamental principle were annotated both as “A2, evaluative” and “B1, relational”. These double-tagged cases were included in both categories when tallying the frequency distributions of the semantic categories (e.g., the basic factor was counted once as A2 and once as B1).
Table 2. Reference and Present Semantic Coding Schemes.
| Semantic taxonomy in Biber et al. (1999) | Semantic taxonomy in Biber & Gray (2016) | Present taxonomy adapted from Biber & Gray (2016) |
| A. Descriptor A1. color A2. size/quantity/extent A3. time A5. miscellaneous descriptive A4. evaluative/emotive |
A. Descriptor A1. physical descriptor A2. evaluative descriptor |
A. Descriptor A1. physical descriptor A2. evaluative descriptor |
| B. Classifiers B1. relational/classificational/restrictive B2. affiliative classifiers B3. topical/other |
B. Classifiers B1. relational classifier B2. topical classifier |
B. Classifiers B1. relational classifier B2. topical classifier C. Ordinals |
Developmental analysis of early-learned adjectives in AAN constructions. As elementary school students produced a limited set of adjectives, we only found 33 adjectives that were used in all three sub-corpora. Therefore, this part of the analysis focused on the 33 adjectives (Table 3) shared by the three sub-corpora, which were called early-learned adjectives in AAN constructions as they were used since the elementary school level.
Table 3. Adjectives Shared by Three Sub-corpora.
| ancient | fourth | rare |
| big | giant | round |
| beautiful | good | same |
| blue | green | second |
| clean | left | short |
| colorful | little | small |
| cute | long | strong |
| entire | lovely | third |
| fifth | national | western |
| fine | physical | white |
| first | primary | whole |
Synonymous (big-giant, entire-whole), antonymous (big-small, long-short) and taxonomic relations (blue-green-white, first-second-third-fourth-fifth) exist among many of the early-learned 33 adjectives. All five semantic classes of adjectives are covered, including for example big in the descriptive-physical class, beautiful in the descriptive-evaluative class, left in the classifying-relational class, physical in the classifying-topical class and fifth in the ordinal class.
To examine changes in the adjective use in the three datasets, the frequency ratio, adjective-to-construction contingency and dispersion of adjectives were calculated. The frequency ratio was the ratio of individual adjective token frequency in AAN against the sum token frequency of all AAN adjective-fillers. Adjective-to-construction contingency was measured with adjective-to-construction ΔP. We first tallied the frequency of a specific adjective (e.g., big) in AAN constructions and in the entire dataset, using both a Python code and Excel functions. Then the “Coll.analysis V3.2a” R script package (Gries, 2007) was used with this information to compute ΔP. Dispersion was the proportion of texts with the target AAN against the total number of texts in each sub-corpus.
Using the three measures as three axes, the Python Matplotlib function was used to visualize the three-dimension distribution of the 33 adjectives in AAN constructions across the three learner groups.
Results and Discussion
Diversity of AAN
Table 4. AAN Raw and Normalized Type Frequency across Levels (topics uncontrolled).
| Level | Words | AAN raw type frequency |
AAN normalized type frequency (per 10,000) |
| EL | 5,446 | 197 | 94.5 |
| MS | 370,710 | 5,955 | 160.6 |
| UN | 1,327,173 | 23,907 | 180.1 |
Overall, the university-level (UN) students used a larger set of more diverse AAN constructions (180.1) than elementary (EL) and middle/high school (MS) students (94.5 and 160.6 respectively). However, the three sub-corpora vary in terms of topic variability. The full EL sub-corpus contains 13 different topics, the MS sub-corpus about 1476 topics and the UN sub-corpus 3810 topics [1]. Given that a wider scope of topics has the potential to lead to a more diverse set of constructions, it is possible that differences in AAN diversity shown in Table 4 are due to different degrees of topic variability in the three sub-corpora. To address this, we analyzed the diversity of AAN in essays on the same topic of “school/university” (see Table 5). With writing topic controlled, AAN types in the MS dataset are fewer than the EL dataset, indicating less construction diversity among MS learners than EL learners for the selected topic. Construction diversity in the UN dataset (121.2) still surpasses the EL and MS datasets (72.0 and 46.6), however. Based on these analyses, university students appear to use a more diverse set of AANs than elementary and middle/high school students.
Table 5. AAN Raw and Normalized Type Frequency across Levels (topics controlled).
| Sub-Corpus | Texts | Words | AAN raw type frequency |
AAN normalized type frequency (per 10000) |
| EL | 32 | 3750 | 27 | 72.0 |
| MS | 56 | 5793 | 27 | 46.6 |
| UN | 37 | 6515 | 79 | 121.2 |
Zipfian Distribution of Adjectives in AAN Constructions in Each Group of Students
Figure 1 shows the rank-ordered token frequencies of adjectives in AAN constructions in each sub-corpus. There is a leading adjective type in each plot. The frequency difference between the leading member and the other members is clearer in the MS and UN datasets than in the EL dataset. A higher density of the data points at the lower part of the plot indicates more adjective types in the lower frequency band compared to the top frequency band. The UN dataset additionally included more adjective types than the other two datasets as shown by an overall higher density of data points.
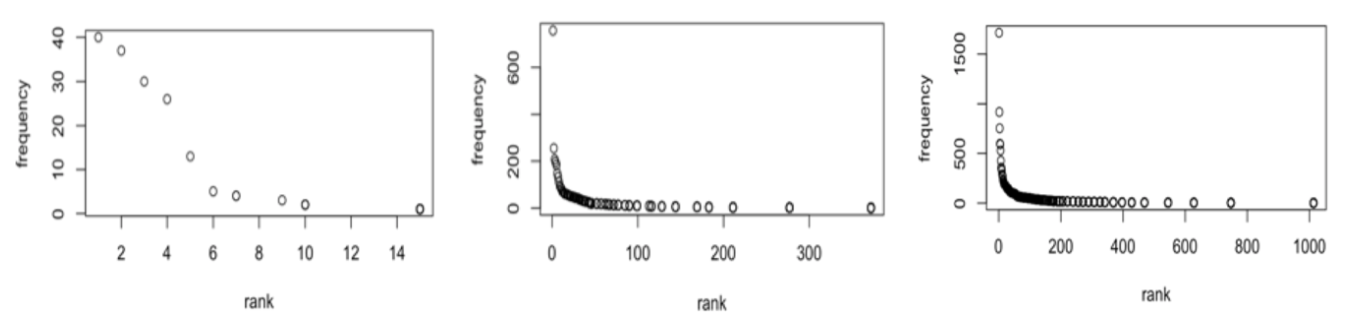
Figure 1. Frequency vs. Frequency Rank for Adjectives in AAN in the EL Dataset (left), MS Dataset (center), and UN Dataset (right).
Figure 2 also shows the type-token distribution plots for the three sub-corpora. All three plots contain hapax legomena, that is, words that occurred only once (frequency is 1 and logged frequency is 0). A linear relationship between logarithmic token frequency and logarithmic adjusted frequency rank for adjectives in AAN was observed in the EL dataset (R2= .97, g = -2.68) (the left-hand plot in Figure 2). Ordinal words were at the top of the list. Physical attributive words such as big follow after the ordinal words. The high frequency of these words in particular may be related to the topics that elementary school students use in class, namely, my school and my favorite animal. A closer reading of the EL essays showed, for example, that when describing their school, students tended to describe the floor/level where their classroom was located, thus often requiring ordinal words (e.g., the first floor, the third floor). The other topics also tend to elicit specific adjective types, such as physical attributives for describing the appearance of animals. These two topics could be seen to align with expectations for L2 writing abilities among elementary school students. This is because these topics are close to real life and arguably make use of language resources for more tangible entities.
Similar to the EL dataset, there is a linear relationship between logarithmic token frequency and logarithmic adjusted frequency rank in the MS dataset (R2 = .98, g = -.66) (the center plot in Figure 2). The generic evaluative adjective good and great are the top two, followed by new, other and first. There were many more word types in the MS dataset than in the EL dataset.
The regression line for the UN dataset (right-hand plot in Figure 2) explained 96.67% of the variance in the type-token distribution of adjectives in the UN dataset (R2 = .97, g = -.62). There were more word types at the lower frequency levels than the previous two plots. Similar to the MS dataset, the words good, other, same, great, new, first remained at the top frequency band. Table 6 lists the top 10 adjectives in each dataset and further shows remarkable similarity of top members across the three datasets.
Table 6. Top 10 Adjectives in AAN in Three Sub-corpora.
| EL | MS | UN |
| second (40) | good (756) | good (1714) |
| first (37) | great (255) | other (918) |
| fourth (30) | new (207) | same (754) |
| third (26) | other (196) | great (598) |
| big (13) | first (184) | first (593) |
| short (5) | big (148) | new (530) |
| long (4) | same (132) | long (426) |
| western (4) | long (111) | important (355) |
| beautiful (3) | beautiful (94) | old (353) |
| cute (2) | English (87) | big (329) |
Further inspection of the full list of adjectives in AANs shows between-group differences for the low-frequency slot-fillers, but less for the high-frequency slot-fillers. In other words, it is the low-frequency slot-fillers that appear to distinguish university students from elementary and middle/high school students.
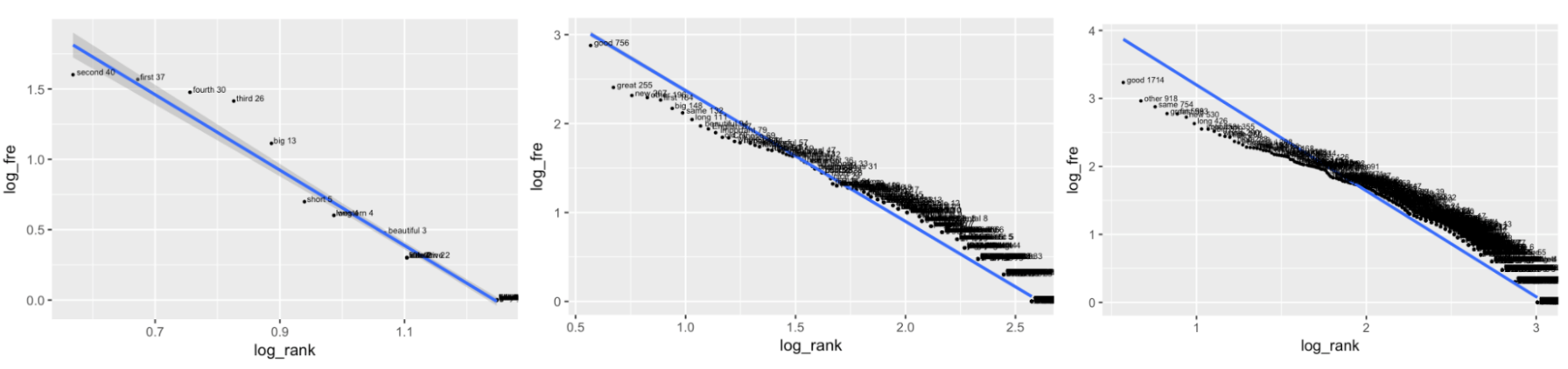
Figure 2. Log Frequency vs. Log Adjusted Frequency Rank for Adjectives in AAN in the EL Dataset (left), MS Dataset (center), and UN Dataset (right).
Changes in Semantic Distribution of Adjectives in AAN
Table 7 summarizes the semantic categories of adjectives in AANs (with examples) in the present corpus.
Table 7. Semantic Taxonomy of Adjectives in AAN.
| Semantic categories | Examples in the present corpus |
| A1. Physical | A1. an aged person, a big city, the dark night |
| A2. Evaluative | A2. an amazing improvement, the critical part, an effective way |
| B1. Relational | B1. the above analysis, the average age, a different person, the final paragraph |
| B2. Topical | B2. the academic achievement, a bilingual dictionary, a Chinese restaurant |
| C. Ordinal | C. the first time, the fifth month |
Table 8 shows the frequency rank of each dataset, indicating that the semantic distribution of adjectives changes with the grade level. Adjectives in category C (ordinals) were the most frequent in the EL dataset and the A1 (physical) category ranked second. B1 (relational), A2 (evaluative), and B2 (topical) categories of adjectives denoting more abstract meanings were used less frequently. The frequencies of the top two categories, C and A1, decreased with the grade level, while the A2 (evaluative) and B2 (topical) categories were at a higher ranking in the UN dataset.
Table 8. Distribution of the Semantic Categories of AANs.
| Rank | EL | MS | UN | |||
| Category | Frequency | Category | Frequency | Category | Frequency | |
| 1 | C | 135 | A2 | 2524 | A2 | 11091 |
| 2 | A1 | 33 | B1 | 1294 | B2 | 5152 |
| 3 | B1 | 13 | A1 | 1138 | B1 | 4121 |
| 4 | A2 | 12 | B2 | 694 | A1 | 2609 |
| 5 | B2 | 4 | C | 273 | C | 873 |
| Error | 6 (2.97%) | 34 (.57%) | 24 (.86%) | |||
| Tag error | 0 | 5 | 130 | |||
| Sum | 203 | 5962 | 24000 | |||
Notes: 1. Frequency = raw frequency counts.
2. Error = learner errors.
3. The sum numbers in the last row for MS and UN column are greater than the total token frequency of AAN in the sub-corpora due to overlap between A2 and B1 categories, for example, ‘the basic skills’, ‘a fundamental cause’, ‘the central idea’ etc. were labelled and counted in both categories.
4. The sum number in the last row for EL column is greater than the total token number due to instances dually labelled with Error and C, for example, ‘the third fioor’.
Identified learner errors were either inappropriate semantic collocations (e.g., a complete college, the donated family) or spelling errors (e.g., a beatiful place, the third fioor). The elementary dataset had the highest error percentage, followed by the university dataset and lastly the middle/high school dataset (2.97% in EL > .86% in UN > .57% in MS). We searched words including afraid (48), alone (21), asleep (14), and awake (2) in the corpus. The results showed that those words were indeed used by the students (the word token frequency in our corpus is indicated in parenthesis following the word), but none of them were used in AAN constructions. For example, a search of asleep in our corpus returned appropriate examples like fell asleep and inappropriate ones such as fall in asleep, when their child asleep, etc., but no example was found for inappropriate use of asleep in AAN, for instance, *the asleep boy (Goldberg, 2019, p.3).
Developmental Changes in the Use of Early-learned Adjectives in AANs
Analyses of the 33 adjectives shared by the three datasets provide insights into the development of adjectives in AANs in L2 writing. Figures 3 to 5 show different angles of the same three-dimensional (frequency ratio, adjective-to-construction contingency, and dispersion) plot of the distribution of these adjectives.
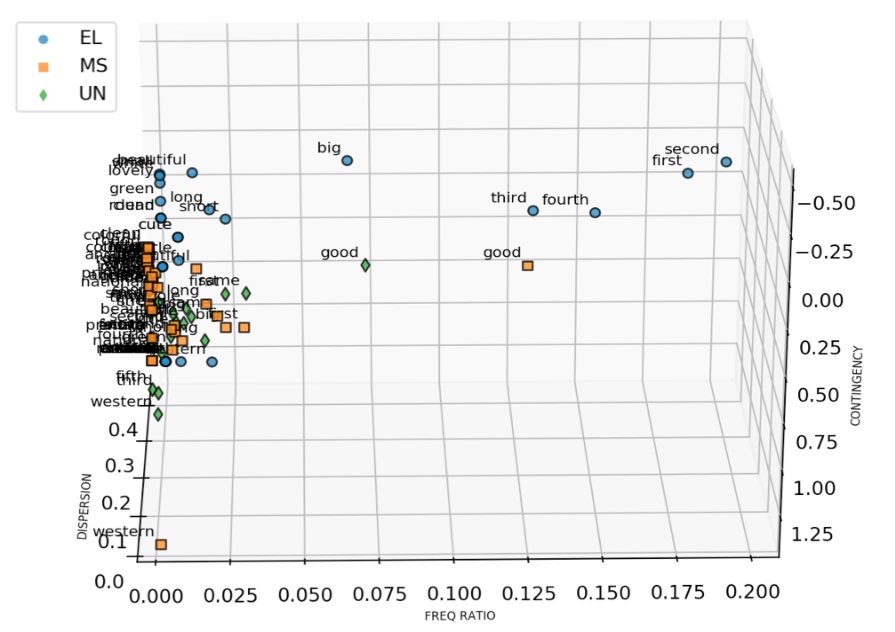
Figure 3. Frequency Ratios of AANs with Specific Adjectives across the Three Groups.
Notes: Data points represented by the green diamond symbol come from the UN dataset; points labelled by yellow square are from the MS dataset; points labelled by blue dots are from the EL dataset.
Figure 3 shows the frequency ratios of the AANs with specific adjectives against the total AAN token frequency. The frequency ratios of the 33 adjectives generally decreased with the grade level. Most data points from the UN dataset are located at the lower end of the frequency ratio axis. This can be explained by the increasing diversity of adjective types in AANs as learners accumulated more vocabulary and construction types. The ordinal words had the highest frequency ratio in the EL dataset, while the generic evaluative word good accounted for a comparatively large frequency ratio in the MS and UN datasets.
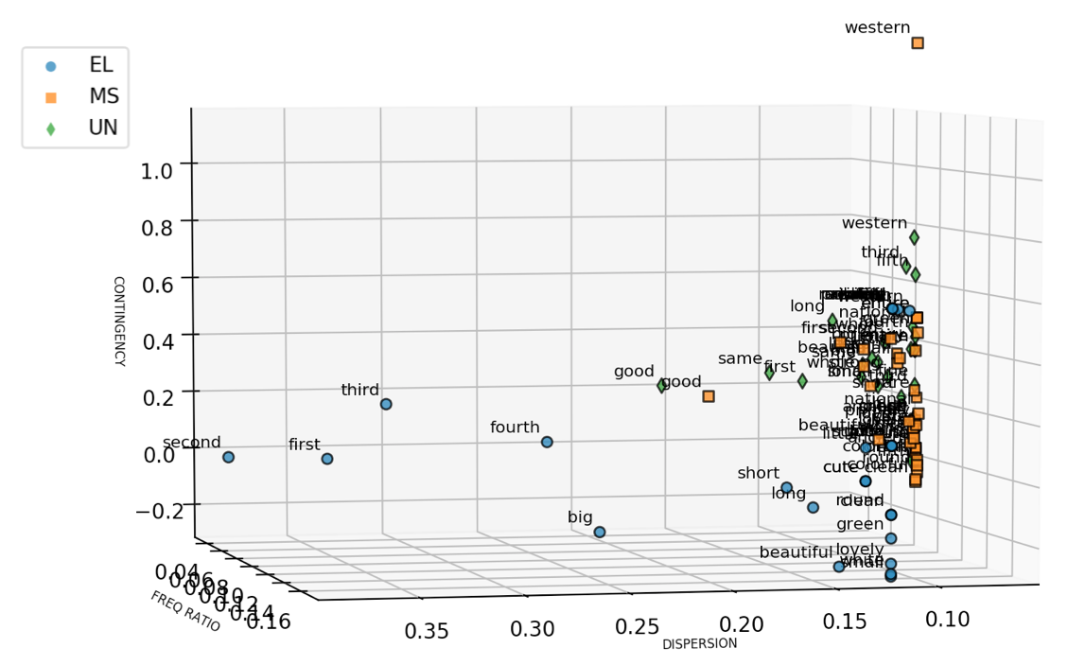
Figure 4. Contingency of Specific Adjectives to AANs across the Three Groups
Figure 4 presents the same three-dimensional plot from the adjective-to-construction contingency perspective (the vertical axis). The word western was the most faithful adjective to the AAN construction in MS and UN datasets, indicating an above-chance probability for the adjective western to occur in AANs. Ordinal words such as first, third were also strongly attracted to the AAN constructions as they were located higher on the contingency scale than other adjectives from the same dataset. Adjectives in the UN and MS datasets seemed to have higher mean contingency values than the words from the EL dataset, as the blue dots occupied the lower part of the plot while the yellow squares and green diamonds formed a cluster above most blue dots. This indicates that the early-learned adjectives in general become more associated with the AAN constructions with an increasing grade level.
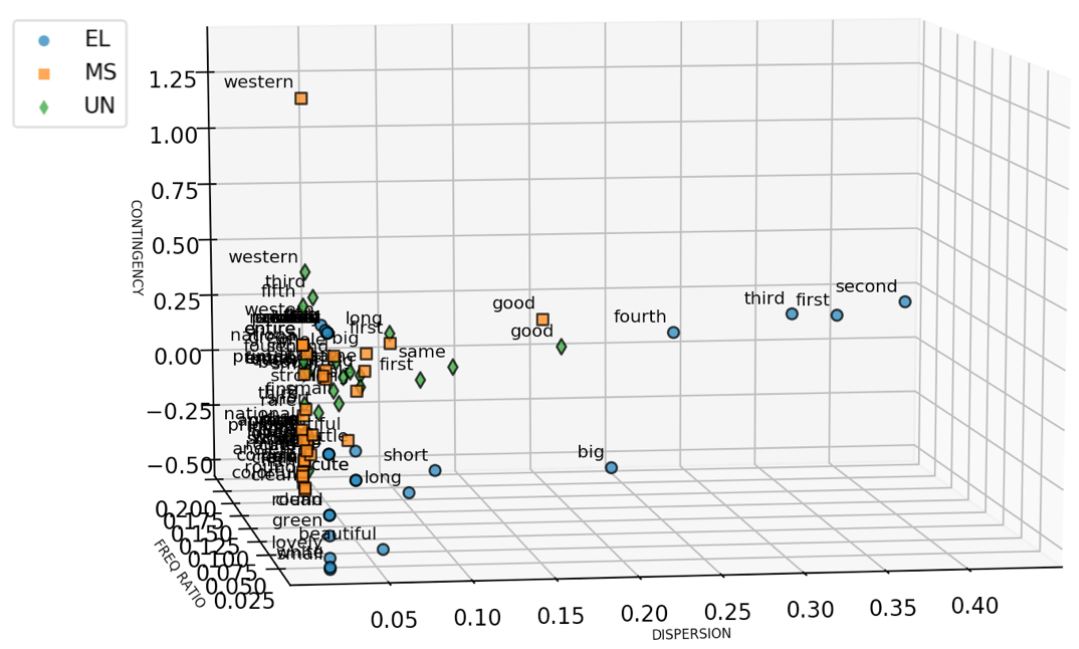
Figure 5. Dispersion of AANs with Specific Adjectives in the Three Sub-corpora.
Dispersion of AANs in the sub-corpora points to the proportion of texts that contained AANs with particular adjectives. Figure 5 shows that a group of ordinals had the highest dispersion values in the EL dataset, among which first also had a higher dispersion in MS and UN datasets. The word good was used extensively in the MS and UN sub-corpora. Other adjectives with more specific semantics were at the lower end of dispersion, which means they were used in a comparatively smaller proportion of texts.
Conclusion
The present study investigated “article + adjective + noun” (AAN) constructions in a learner corpus of L2 English writing. The corpus design which included learners from three grade levels (elementary school, middle/high school, and university) allowed us to investigate the extent to which learners’ use of constructions in L2 writing varied as a function of exposure to and/or experience with English. Our findings showed that AAN constructions were much more diverse in the university dataset in comparison to the middle/high school and elementary school datasets. This finding suggests that university learners likely possess a larger and more diversified repertoire of L2 resources. Considering that English is a compulsory subject in China’s schools and colleges (i.e., all students in the state education system study English over the course of their education), students’ expanding repertoire of AANs could be the result of increased L2 experience over time. In other words, learners in the university dataset will have studied English for the longest amount of time compared to the elementary and middle/high school learners. This factor could be one explanation for why university students’ repertoire of AAN constructions appeared the most diverse. This group of learners have likely been exposed to English for a longer amount of time. That said, longitudinal research is required that documents learners’ language usage over an extended period of time to further understand the developmental trajectory of constructions in Chinese EFL learners. Furthermore, triangulation of usage data with data about language exposure could further indicate the nature of the exposure-usage relationship in L2 learning.
In addition, several leading adjectives accounted for a large portion of all adjective tokens in AAN constructions. These leading members were generic in meaning, in line with the findings of previous studies (Ellis & Ferreira-Junior, 2009a; Ellis et al., 2016). Ordinal words (e.g., first) and big were most used by elementary school students. The distribution of adjective types in the MS and UN sub-corpora was near-Zipfian, with good, great, other being the most frequent in both datasets. The near-Zipfian type-token distributions of adjectives in AANs add further support to previous research showing that constructions tend to have core members driving development (Ellis et al., 2016). Furthermore, the long tail in each type-token distribution plot points to the fact that the majority of word types are rarely used. Due to the large overlap in top members, inter-group differences lie more at the low-frequency band instead of the top-frequency band. In other words, “advancedness” may be determined by the less frequent items, that is, at the tail of the Zipfian distribution.
In terms of frequency distribution of the five semantic categories of adjectives, our results showed important between-group differences: lower-grade students used more ordinal and descriptive adjectives while higher-grade students used more evaluative and topical adjectives. Contrary to what we would expect, adjectives incompatible with the AAN construction were not observed in the present corpus of Chinese EFL student writing.
The frequency ratios of the 33 early-learned adjectives in AANs decreased with grade level, whereas the adjective-to-construction contingency increased with the grade level. Overall, ordinal words and good topped the early-learned adjectives in all three dimensions, which can be regarded as the prototypical adjectival slot-fillers of the AAN construction.
Pedagogical Implications of Findings
The present study’s finding could be helpful for EFL instructors to better understand EFL learners’ language. In particular, these findings have the potential to advance understanding about the ways in which the writing needs of L2 users in using AANs can be supported. Furthermore, these findings could contribute to the design of pedagogical interventions to enhance EFL learners’ knowledge and use of AANs. For example, elementary school EFL teachers could introduce the 33 early-learned adjectives identified in the current study as path-breaking adjectives for AAN constructions, thus providing targeted, bootstrapped support for L2 learning. EFL teachers in higher grade classes could additionally incorporate diverse AANs using less frequent adjectives to enrich students’ inventory of AANs. It is possible the pedagogical interventions incorporating these evidence-based recommendations could benefit language development. However, further empirical work is needed to more fully understand connections between specific pedagogical methods and learning outcomes.
In addition, these findings also have implications for usage-based approaches to language teaching that emphasize the ways in which features and qualities of the input and the instruction contribute to learning outcomes (e.g., Tyler & Ortega, 2018). With growing interest in understanding the ways in which language teaching may benefit from greater sensitivity and awareness of constructions (e.g., De Knop & Gilquin, 2016), empirical studies are beginning to garner evidence about the ways in which constructional meaning emerges and what the routes and rate of development are for this type of knowledge (e.g., Achard & Niemeier, 2008; Cadierno & Eskildsen, 2015). However, as previously noted, our understanding of constructions in L2 learning still represents a novel and under-researched line of inquiry. Further empirical research is needed that documents the emergence of a variety of different construction types. For example, out findings suggested few challenges for EFL in the use of AAN constructions. That is, AAN usage was productive among elementary and middle/high school students who seemed able to use the full scope of semantic classes of the AAN construction and seldom used illegitimate adjectives for this construction. One interpretation of this finding could be that exposure to AAN constructions alone might be a sufficient condition for L2 learning without the need for subsequent targeted instruction that draws learners’ attention to specific aspects of the language. This, however, requires more research that tracks not only the types of language used in EFL classrooms, but more longitudinal studies that track the emergence development of specific constructions.
Limitations and Future Directions
The adjective-noun contingency in AAN was not examined in the present study. Insights from adjective-noun collocation research should be incorporated into the multi-word construction analysis in the future.
Though grammarians have noted some words are not permitted in AANs, we did not find any evidence for the violation of constructional restriction of AANs in our corpus. This may arguably due to the inadequacy of research data from the beginning-level students, the conservativeness of student writers in language use in an assessment-oriented context, or that adjectives incompatible with the AANs were simply rarely used for the essay topics in the corpus. These issues could be addressed through replication (Porte & McManus, 2019) using different learner corpora. In addition, psycholinguistic experiments could serve as a direct, effective method to elicit learners’ knowledge of constructional restrictions.
Due to the wide distribution of the population who contributed to the TECCL corpus, it was hard to build a corpus that represents language input for the students. A comprehensive survey of the text books and instructional materials in China can be undertaken to build a corpus for this purpose. Further research is still needed to validate the relationship between language input and use of AANs.
Notes
[1] The full list of essay topics in the corpus can be downloaded together with the corpus from https://mailman.uib.no/public/corpora/2016-February/024014.html. The number of topics were roughly calculated because the topics were entered into the online platform by students with typos, extra spaces, and spelling mistakes, which may lead to miscalculation of the number of topics.
About the Authors
Yingying Liu is a Ph.D. candidate in the Department of Applied Linguistics at The Pennsylvania State University. Her research interests include corpus linguistics, English for Academic Purposes, English phraseology, and lexicography.
Kevin McManus is Associate Professor and Watz Early Career Professor in the Department of Applied Linguistics at The Pennsylvania State University, USA. He is also Director of the Center for Language Acquisition. His research specializations include second language acquisition and replication research.
Acknowledgements
The authors would like to thank Alex Magnuson for his help with data coding; Jiajin Xu who developed the TECCL corpus; and the audience at the Applied Linguistics Roundtable at the Pennsylvania State University and at SLRF 2018 in Montréal, Quebec for helpful discussion and suggestions.
References
Achard, M., & Niemeier, S. (Eds.). (2008). Cognitive linguistics, second language acquisition, and foreign language teaching. Mouton de Gruyter.
Anthony, L. (2018). AntConc (Version 3.5.7) [Computer Software]. Retrieved from http://www.laurenceanthony.net/
Bencini, G., & Goldberg, A. (2000). The contribution of argument structure constructions to sentence meaning. Journal of Memory and Language, 43(4), 640–51.
Biber, D., Johansson, S., Leech, G., Conrad, S., & Finegan, E. (1999). Longman grammar of spoken and written English. Longman.
Biber, D., & Gray, B. (2016). Grammatical complexity in academic English: Linguistic change in writing. Cambridge University Press.
Cadierno, T., & Eskildsen, S. W. (Eds.). (2015). Usage-based perspectives on second language learning. Walter de Gruyter.
Ellis, N. C. (2006). Language acquisition as rational contingency learning. Applied Linguistics, 27(1), 1-24.
Ellis, N. C., & Ferreira-Junior, F. (2009a). Construction learning as a function of frequency, frequency distribution, and function. The Modern Language Journal, 93(iii), 370–385.
Ellis, N. C., & Ferreira-Junior, F. (2009b). Constructions and their acquisition: Islands and the distinctiveness of their occupancy. Annual Review of Cognitive Linguistics, 7, 187-220.
Ellis, N. C., O’Donnell, M. B., & Römer, U. (2014). Second language verb argument constructions are sensitive to form, function, frequency, contingency, and prototypicality. Linguistic Approaches to Bilingualism, 4(4), 405-431.
Ellis, N. C., O’Donnell, M. B., & Römer, U. (2015). Usage-based language learning. In B. MacWhinney & W. O’Grady (Eds.), The handbook of language emergence (pp. 163-180). Wiley.
Ellis, N. C., Römer, U., & O’Donnell, M. B. (2016). Usage-based approaches to language acquisition and processing: Cognitive and corpus investigations of construction grammar. Wiley.
Eskildsen, S. W. (2009). Constructing another language – Usage-based linguistics in second language acquisition. Applied Linguistics, 30, 335-357.
Eskildsen, S.W., Cadierno, T., & Li, P. (2015). On the development of motion constructions in four learners of L2 English. In T. Cadierno & S. W. Eskildsen (Eds.), Usage-based perspectives on second language learning (pp. 207–232). Walter de Gruyter.
Fillmore, C. J., Lee-Goldman, R. R., & Rhodes, R. (2012). The FrameNet construction. In H. C. Boas & I. A. Sag (Eds.), Sign-Based construction grammar (CSLI Lecture Notes 193), 309–372. CSLI Publications.
Francis, G., Hunston, S., & Manning, E. (1996). Collins COBUILD grammar patterns 1: Verbs. HarperCollins.
Francis, G., Hunston, S., & Manning, E. (1998). Collins COBUILD grammar patterns 2: Nouns and Adjectives. HarperCollins.
Goldberg, A. E. (1995). Constructions: A construction grammar approach to argument structure. University of Chicago Press.
Goldberg, A. E. (2006). Constructions at work: The nature of generalization in language. Oxford University Press.
Goldberg, A. E. (2019). Explain me this: creativity, competition, and the partial productivity of constructions. Princeton University Press.
Goldberg, A. E., Casenhiser, D. M., & Sethuraman, N. (2004). Learning argument structure generalizations. Cognitive linguistics, 15(3), 289-316.
Gries, Stefan. Th. (2007). Collostructional analysis (Version 3.2a) [Computer Software]. Retrieved from http://www.stgries.info/teaching/groningen/index.html
Gries, Stefan. Th., & Wulff, S. (2005). Do foreign language learners also have constructions? Evidence from priming, sorting, and corpora. Annual Review of Cognitive Linguistics, 3, 182– 200.
Hunston, S., & Su, H. (2019). Patterns, constructions, and local grammar: a case study of ‘evaluation’. Applied Linguistics, 40(4), 567-593.
Ihaka, R., & Gentleman R. (1996). R: a language for data analysis and graphics. Journal of Computational and Graphical Statistics, 5, 299–314.
Li, P., Eskildsen, S. W., & Cadierno T. (2014). Tracing an L2 learner’s motion constructions over time: A usage-based classroom investigation. The Modern Language Journal, 98(2), 612-628.
Merriam-Webster. (2008). Merriam-Webster’s advanced learner’s English dictionary.
Patten, A. L., & Perek, F. (In press). Pedagogic applications of the English construction. In H. Boas (Ed.), Pedagogic construction grammar: Data, methods, and applications. Mouton de Gruyter.
Pearson Education. (2003). Longman dictionary of contemporary English. Longman.
Plonsky, L., & Ghanbar, H. (2018). Multiple regression in L2 research: A methodological synthesis and guide to interpreting R2 values. The Modern Language Journal, 102(4), 713-731.
Porte, G., & McManus, K. (2019). Doing replication research in applied linguistics. Routledge.
Römer, U. (2009). English in academia: Does nativeness matter? Anglistik: International Journal of English Studies, 20 (2), 89-100.
Römer, U. (2019). A corpus perspective on the development of verb constructions in second language learners. International Journal of Corpus Linguistics, 24(3), 270-292.
Römer, U., O’Donnell, M., & Ellis, N. C. (2015). Using COBUILD grammar patterns for a large-scale analysis of verb-argument constructions: Exploring corpus data and speaker knowledge. In Groom, N., Charles, M., & John, S. (Eds.), Corpora, grammar, text and discourse: In Honour of Susan Hunston (pp. 43-71). John Benjamins.
Siyanova, A., & Schmitt, N. (2008). L2 learner production and processing of collocation: A multi-study perspective. The Canadian Modern Language Review, 64(3), 429-458.
Stefanowitsch, A., & Gries, S. T. (2003). Collostructions: Investigating the interaction of words and constructions. International Journal of Corpus Linguistics, 8(2), 209-243.
Taylor, J. R. (2003). Linguistic categorization: Prototypes in linguistic theory. Oxford University Press.
Tyler, A. E., & Ortega, L. (2018). Usage-inspired L2 instruction: An emergent, researched pedagogy. In Tyler, A. E., Ortega, L., Uno, M., & Park, H. I. (Eds.). Usage-inspired L2 instruction: Researched pedagogy (pp. 3-28). John Benjamins.
Xue, X. (2015). Ten-thousand English compositions of Chinese learners (The TECCL corpus). Retrieved from https://mailman.uib.no/public/corpora/2016-February/024014.html
Appendix
Table A1. Topics in Diversity Analysis (topics controlled)
| Sub-corpus | Topics included | Number of texts |
| UN | 1. Beautiful campus 2. Into university 3. My college 4. My dream university 5. My high school 6. My school 7. My university 8. The most interesting place on campus 9. This is my college 10. University vision 11. Welcome to visit to our college 12. Welcome to G building 13. Welcome to our school |
37 |
| MS | 1. Highlights of my school 2. My favorite place at school |
57 |
| EL | 1. My school | 32 |
[back to Corpus] [back to Analyses]
| Copyright rests with authors. Please cite TESL-EJ appropriately. Editor’s Note: The HTML version contains no page numbers. Please use the PDF version of this article for citations. |