

December 2000 — Volume 4, Number 4
Something Old, Something New, Something Borrowed, Something….: Piloting a Computer Mediated Version of the Michigan Listening Comprehension Test
Greta J. Gorsuch
Texas Tech University
<greta.gorsuch@TTU.EDU>
Tom Cox
Texas Tech University
<tcox@ttacs.ttu.edu>
Abstract
When commercially produced proficiency tests are used to make decisions such as exemption from or retention in language programs, it is necessary to conduct analyses on the test data at the local level. The purpose of such analyses is to identify and estimate sources of measurement error. In other words, we must investigate the extent to which we can trust students’ results on the test. This report recounts the use of a computer mediated proficiency test in an intensive international teaching assistant workshop. Both traditional raw score analyses and item response theory analyses done on the test data are described in detail. They indicated that for reasons related to the test itself and to the computer mediated version of it, the test was not suitable for making exemption and retention decisions with this particular group of students in this particular program.
Introduction
This report has three ingredients:
Something old: The English Language Institute Listening Comprehension Test, Form 4 (ELILCT), also known as “The Michigan Listening Comprehension Test” (Testing and Certification Division, 1972).
Something new: A computer mediated examination program in the Texas Tech University Language Learning Lab.
Something borrowed: Item response theory (IRT), “borrowed” from the field of general education measurement.
In July, 2000, a computer mediated version of the ELILCT (Form 4) was administered to 40 participants at the beginning of an intensive international teaching assistant (ITA) training workshop at Texas Tech University. The test was administered for two reasons:
- to aid in making workshop exemption and retention decisions; and
- to analyze the data from the test administration, using both raw score analyses and item response theory analyses. This was done to determine whether the ELILCT yielded helpful information in making exemption and retention decisions.
[-1-]
Research questions #1 and #2 below respond to the first reason for test administration, and research questions #3 and #4 respond to the second reason:
- Was the ELILCT suitable for use in making program exemption and retention decisions for participants in the Summer 2000 International Teaching Assistant Workshop?
- What were the differences in hypothetical student program exemptions and retentions using student total raw scores compared to item response theory student ability estimates?
- Did the computer-mediated version of the ELILCT, using the manual version DI 8 Multi-Media Centre examination program, produce reliable results?
- What were test takers’ and test proctors’ reactions to the computer mediated version of the ELILCT?
Using computer mediated norm-referenced tests . For reasons of convenience, many second language testers elect to administer multiple choice tests using computers. The most important advantage is that students’ test data can be downloaded into a data file and then later analyzed at the item level (item by item) without the time consuming step of inputting students’ scores from answer sheets into a computer by hand. In testing situations where time pressure is an issue, having the test data available for a variety of immediate and in-depth analyses is invaluable.
However, despite the advantages of computer mediated testing, there are some potential threats to test reliability. Brown (1996, pp. 188-192) warns against measurement error caused by environmental factors (noisy rooms), test administration procedures (faulty equipment), examinees (fatigue), scoring procedures (rater subjectivity), and test items (item quality). Measurement error due to examinees, scoring, and test administration procedures are of particular interest for this study. For instance, if the students are unfamiliar with taking computer-mediated tests, their unfamiliarity may cause them to answer questions incorrectly that they might otherwise get correct. This may increase measurement error. Further, when computer technology works, it is efficient and elegant. But when it does not work, problems may ensue. One very real problem is that when computer errors in scoring or test administration occur, it may be difficult to pinpoint the problem, or even to know that the problem is occurring while the test is underway. In the case of the test used in this study, it became apparent that on some items, students were pressing response buttons for their answer choices, but their responses did not register in the computer program. Potential problems such as those described above make thorough analysis of test results even more imperative.
This is not to dissuade readers from using computer-mediated tests. Rather, it is strongly argued here that to detect and compensate for measurement error, testers must have the data to analyze to begin with, something which computer-mediated testing will provide. Manual testing and test scoring (using answer sheets and pencils) is just as prone to measurement error as computer-mediated testing, and given tight time constraints, manual test scoring may not provide testers the data they need to adequately analyze the test results.
Manual test scoring . Manual scoring of the ELILCT is still used in some U.S. university ESL programs. A typical manual scoring procedure is as follows:
When students finish the test, their answer sheets are collected and then sent to a room with several human test scorers. They are given a plastic template of correct scores which is laid over the students’ answer sheets, one by one. The scorers mark which items are wrong by locating “blank windows” in the template (points at which the students’ pencil mark should have been visible through the template if they had answered the items correctly). The template is then removed and the correct answers counted up and marked on a separate student score report sheet. The data analysis involves converting students’ total raw scores on a “score equating chart.” The “equated LCT [ELILCT] are not the percentage correct, but rather scores adjusted to the scale used on the other components of the Michigan proficiency battery” (English Language Institute, 1986, p. 10). Students are then exempted from, or retained in, ESL courses on the basis of their combined equated scores.
[-2-]
No other components of the “Michigan proficiency battery” were administered at the ITA workshop, and the “equated scores” gave no information as to students’ percentile scores as compared to the norming group of the ELILCT. Therefore, it made more sense to investigate the appropriateness of making exemption decisions using students’ raw scores as the basis of analysis.
Implications of making decisions based on total raw scores . Having only total raw scores limits what one can do to ensure that appropriate decisions are made. Having only the total raw scores does not allow for the calculation of one classical item analysis–item discrimination. Without item discrimination analysis, it is not possible to know which test items are discriminating between high and low scoring students. Students’ total raw scores would allow for calculation of standard error of measurement, however. One standard error of measurement formula used by Brown (1996, p. 207) requires both the standard deviation of a test (which could be estimated from students’ total raw scores), and a reliability estimate of a test (which could be calculated using the conservative K-R21 formula, Brown, 1996, p. 197). If, for example, the standard error of measurement of the ELILCT was estimated to be 4, a student receiving a score of 30 would have a 68% chance of getting a score as low as 26 (or, 30 – 4 = 26) or as high as 34 (or, 30 + 4 = 34) if they were to take the test again. If the raw score cut score was determined to be 32 and students with scores of 32 and above were exempted from a program, the student with a score of 30 might be unfairly retained in an ESL program. According to the standard error of measurement, there is a reasonable chance that if they took the test again, they could get a score as high as 34, which would exempt them from the program (see Brown, 1996 for a more complete explanation of standard error of measurement).
There is one problem with using standard error of measurement estimates based on raw scores, however. Lord (in Hambleton, Swaminathan, & Rogers, 1991, p. 4) noted that depending on where students are in the raw score distribution of their test group, they may not have the same standard error of measurement as students in other parts of the distribution. Wherever we create a cut point for exemption or retention in a raw score distribution, there will be varying levels of error in scores clustered around that cut point. The standard error of measurement does not create estimates for individual students. Instead, the standard error of measurement produces one estimate for all students, and will not reveal the actual band of error around scores at different points in the distribution. Therefore, a student with a total raw score of 30 may have a standard error of measurement of 4, while a student with a total raw score of 22 may have a standard error of measurement of 4.8.
Raw scores also tell us is the distribution of students’ scores on the test. By typing the raw scores into statistical program and then requesting a histogram and descriptive statistics, testers can estimate how well the test is spreading students along on the continuum of skills captured by the test. Score distributions that are clustered towards the bottom end of the distribution, or towards the top end would alert testers to the possibility that the test is either too difficult or too easy for the group of students being tested. Such tests may not be suitable for the purposes of making decisions on program exemption or retention, in that the tests that are too easy or too difficult for students actually tell us very little about students’ abilities.
Using item response theory analyses. Item response theory (IRT) analyses provide four important pieces of information not available from using analyses based on students’ total raw scores:
- the student ability estimate;
- individual error estimates;
- item fit maps; and
- case estimate reports.
[-3-]
The student ability estimate is created by focusing on an individual student’s responses that tell the most about a student’s ability. Test items that are too easy for a student tell us nothing, since a student answers without much thought. Items that are too difficult for a student are equally uninformative in that a student will probably guess at the answers. IRT programs, such as Quest 2.1 (Adams & Khoo, 1996), create a probabilistic estimate of a student’s ability, based on items just at the point of difficulty where a particular student is not easily answering items correctly or guessing at answers. Students’ ability estimates are calculated using only the items at a level of difficulty at which students demonstrate that they are 50% likely to get the item right, and 50% likely to get the item wrong.
This feature may create discrepancies in students’ ranking by total raw scores and IRT student ability estimates. Some students who get higher total raw scores may get lower IRT student ability estimates, and conversely, students who get higher IRT student ability estimates may get lower total raw scores. The question arises as to which set of scores should be accepted. Depending on the total sample size, probably the IRT student ability estimates. Even with smaller samples (below 100), where there may be more error in estimation, IRT student ability estimates are likely to be more precise. IRT analyses also offer individual errors for estimates for each student, taking into account only the student’s responses that give us the most information about the student’s ability. Therefore, we would know exactly how much error there is at any given point on a distribution of student ability estimates, something which the standard error of measure based on raw total scores does not supply. After creating a cut score on that distribution, we would know how reliable decisions made at that point would be.
IRT student ability estimates are specific to the test that was analyzed to generate them. The estimates typically range from +3.0 for student with high abilities on the test to -3.0 for students with low abilities. In IRT, test items are rated on the same scale for difficulty according to the data. An item difficulty estimate of +3.0 means “very difficult,” while an estimate of -3.0 means “very easy.” A student with an ability estimate of “0” (i.e., exactly in the middle) has a 50% chance of getting an item with a difficulty estimate of “0” correct. In general, when IRT student ability estimates range from +1.0 to +3.0 or higher, the students’ abilities are very high in comparison with the difficulty levels of items on the test.
IRT programs such as Quest 2.1 also offer an item fit analysis, which can be used to locate test items that are behaving differently from other items. For instance, one or two items may not be tapping into the same abilities as the other test items. Or, the items may not be well constructed, or may be ambiguously worded. Finally, items with values that show a poor fit may indicate that on a large scale, students experienced technical difficulties responding to the question. Perhaps the audio recording malfunctioned at that moment, or, in the case of a computer-mediated test, the computer program malfunctioned.
Quest 2.1 provides case estimates, which is an IRT report on each students’ pattern of responses on the test. Cases that don’t fit may indicate, for example, that students were answering questions randomly, or perhaps were answering correctly but for some technical reason, their responses were not being correctly registered by a computer examination program. Finally, Quest 2.1 provides item distractor analyses for each item (item distractor analysis is not unique to IRT, however, it is just a useful feature of Quest 2.1). This analysis reports how many students answered each of the test response choices in a multiple choice test, “A,” “B,” or “C.” Thus, in addition to telling us how many students answered an item correctly, it reports which of the wrong responses were doing an adequate job of distracting students, therefore discriminating between high and low scoring students. The item distractor analysis also indicates how many students did not answer an item, which may indicate technical problems or problems with item quality. [-4-]
Methods
Subjects
The participants of the International Teaching Assistant Workshop were 40 non-native speakers of English from a wide variety of countries, including Mexico, India, China, Korea, Germany, and Paraguay. The workshop participants had been offered teaching assistantships in a variety of academic departments (Chemistry, Biology, Computer Science, and Political Science, among others) at a medium-sized U.S. state university. Because they were employed to teach first-year undergraduate courses, the university had a mandate to ensure that the teaching assistants had proficient English ability. All workshop participants had been accepted as graduate students in their majors by the university, and therefore had TOEFL scores of at least 550.[1]
Materials
The test used in this report was Form 4 of the ELILCT (English Language Institute, 1986; Testing and Certification Division, 1972). The ELILCT “was created for use as one of the component tests of the Michigan proficiency battery,” and was designed to “assess the English language proficiency of non-native [adult] speakers of English who wish to pursue academic work at colleges and universities where English is the medium of instruction” (English Language Institute (ELI), 1986, p. 1). The three forms of the test available (Forms 4, 5, and 6) at this university have 45 multiple choice items, each with three answer choices. A spoken prompt is heard on a tape recorder, students choose what they think is the most suitable answer, and then mark their responses on a separate answer sheet. The test is considered to be “an aural grammar test” and tests students on grammar structures falling under “grammar classifications” such as “tense/pronoun agreement,” and “correlative conjunctions” (1986, pp. 1-2). One prompt for a “tense/pronoun agreement” item is: Was that a good movie you saw? and students must answer from the three following choices: A. Yes, it is; B. Yes, it was; and C. Yes, I have.
The norming group used to validate the test comprised 1,486 students who took the test in 1983 (ELI, 1986, p. 11). Neither the norming group students, nor their abilities as estimated by other standardized tests, such as the TOEFL, are described. The test developers note that “the LTC [listening comprehension test] is less difficult, for this sample of 1,486 at least, than the MTLEP [other component tests of the Michigan proficiency battery] or the composition components of the battery” (ELI, 1986, p. 11).
The manual examination function of the ASC 4.2 DI 8 Multi Media Centre (1996) program was used to administer the ELILCT. The ASC 4.2 DI 8 Multi Media Centre is a Microsoft Windows-based program that delivers an array of functions to the language lab. Teachers who wish to have all students listen to a tape in the language lab, for example, use the program to choose to which student consoles the recording will be delivered.
The manual examination function is well suited for listening comprehension tests. There is one preliminary step to programming the test: One must listen to the listening comprehension test tape and time how many seconds separate the item prompts. In the case of the ELILCT, the original technician adapting the test to the computer program reported that 12 seconds consistently separated the prompts (this later turned out to be incorrect, which will be discussed below). To program the function, one merely has to tell the computer how many items there are, the correct answers, and how many seconds should be allowed for students to respond after each item. To administer the test, the test proctor plays the tape in the program’s attached tape player. In the manual version, the test proctor presses a central trigger button immediately after an item prompt has finished playing. The students then have a pre-specified time in which to press a button to respond. As soon as the next item prompt is heard on the tape, the program stops registering student responses for the previous item. The program records students’ responses and retains the data for downloading for further analysis. One advantage of the program is that is it very simple to set up and adapt to existing tests. One needs only the cassette tape used for the test. Students have their answer sheets; no test prompts or answer choices have to be typed into a program, as is the case with other computer testing programs. [-5-]
There were two additional data gathering instruments used in this report: a student questionnaire, administered immediately after the examination (N = 40), and a test administrator questionnaire, also administered immediately after the examination (N = 5). The student questionnaire contained seven items and was designed to capture students’ attitudes towards and impressions about potential difficulties produced by the computer-mediated version of the ELILCT. Two items (#1 and 6) were designed to produce nominal data, and four items (#2, 3, 4, and 5) were designed to produce continuous data (these were four-point Likert scales). The final item (#7) was open-ended, and allowed students to make additional comments. (The questionnaire items can be found in the Results section below.) The test administrator questionnaire (also in Results below) contained six items, and was designed to capture test administrators’ impressions of the computer-mediated form of ELILCT. One item was a nominal data item, three items were continuous data items, and two items were open ended, “additional comment” items.
Procedure
The ELILCT (Form 4) was adapted to the computer examination program several weeks before the test administration. For the test administration, each student was seated in a pre-assigned listening booth in a language lab. The students had only an answer choice book, a student console with buttons marked “A,” “B,” and “C” to correspond to the three answer choices for each item, and a small digital display indicating how much time they had remaining to respond to a question. Students, wearing headphones, would hear an item prompt, look at their question book for the answer choices, and then press one of the buttons to answer. The job of the test administrator at the main console was to start the tape, and then press a button immediately after each item prompt to instruct the program to register the students’ responses to the item. After twelve seconds the computer stopped registering students’ responses and the next item prompt on the tape played. After the test was over, the test administrator downloaded the students’ data as text. The data was opened in a word processing program. A portion of the data appears below with students’ names removed:
Table 1
Student data downloaded from the GUI 2.4 DI 8 Multi Media Centre program.
Note: Only four out of forty cases are reported here. |
Explanation: “-” denotes missing data. XXXX indicates the students’ identification number and the console number where they were seated. The two digit numbers to the right, such as “64” indicated the percentage of items students answered correctly. This automatic percentage scoring was one feature provided by the ASC 4.2 DI 8 Multi Media Centre program. The letters then indicated what response button students had pressed for each item. [-6-]
Analyses
Research questions number one and two . Students’ percentage correct scores were converted to total raw scores and entered into Statview 5.0. Descriptive statistics for the total raw scores, including mean, standard deviation, minimum, maximum, skewness, and kurtosis were calculated. K-R21 reliability and the standard error of measurement were calculated using Brown’s formulae (1996, p. 197, 207). To calculate students’ IRT ability estimates and individual error estimates, the data were configured to run on a Rasch IRT analysis program Quest 2.1. A “control card” (an instruction card for the program) was devised and a command included to produce student ability estimates, individual error estimates, and a case summary (which included a K-R20 reliability coefficient for the test). The control card commands for the data analysis appears in Table 2 below:
Table 2
Control card commands for the data analysis
| Command | Purpose of command |
| *Analysis of Michigan Test | Names the analysis |
| header Michigan Listening 2000 | Places the header on output pages |
| set width=70 !page | Sets the limit of the data set width |
| set length=65 | Sets the limit of the data set length |
| * ‘-‘ denotes missing data | Tells the program how to deal with missing data |
| codes ABC | Tells the program all possible responses |
| data michlist.dat | Tells the program which data set to analyze |
| format id 1-12 items 13-57 | Tells the program which columns comprise the data set |
| key BAC….etc. | Tells the program the correct answers for all 45 items |
| estimate !iter=1000 | Tells the program to score and estimate the data, with a cue o terminate after 1000 iterations |
| show>>michout1.txt | Requests program to provide output for case estimates and item estimate map |
| show items>>michout2.txt | Requests program to provide output for item estimates |
| show cases ! order=estimate>>michout3.txt | Requests program to arrange students by student ability estimate in descending order and provide output |
| itanal>>michlist.itn | Requests program to provide an item distracter analysis and provide output |
| quit | Tells program to quit |
[-7-]
The resulting student ability estimates and individual error estimates were entered into the Statview 5.0 document alongside the total raw scores. Statview 5.0 then ranked the students in descending order by total raw scores. A hypothetical cut score was arbitrarily assigned to the raw scores. Discrepancies between the two data sets for both program exemption and retention were noted.
Research question number three . Several outputs from Quest 2.1 were requested (see Table 2 above):
- The item fit map, which produced a visual image of items that were “non-fitting,” indicating potential technical difficulties in response to test questions
- Case estimates (reports on each student’s responses), which could indicate whether some students were responding to the questions randomly.
- The itanal report, a distractor efficiency analysis. This output would indicate how many students chose the three possible answer choices (A,B,C) for each item, and how many missing data points there were for each item. Items with numerous missing data points might indicate technical problems with the computer examination program.
Research question number four . Students’ and test administrators’ responses to their respective questionnaires were reported. For the nominal data items, frequencies were reported. For the continuous data items, descriptive data were reported, including mean, standard deviation, mode, skewness, and kurtosis. For the open-ended items, response themes were identified and counted for frequencies.
Results
Research question #1 . Reported below (Table 3) are the descriptive statistics for students’ total raw scores:
Table 3
Descriptive statistics for students’ total raw scores .
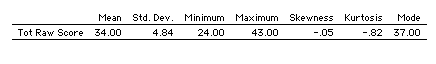
[-8-]
It appears in general that the ELILCT was easy for this group, mirroring the test makers’ comments reported above. Students received a mean score of 34 out of a total possible 45. The mode (37) is slightly higher than the mean (34). There is slight negative skewness, and a relatively high kurtosis coefficient, suggesting a distribution clustered to the right, confirmed in Figure 1 below:
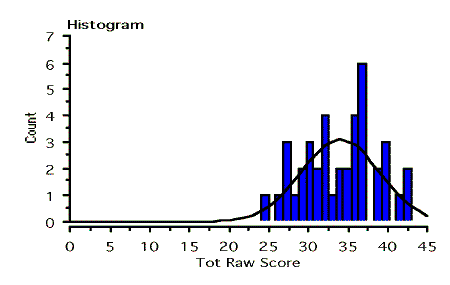
Figure 1: Score distribution of ELILCT
That the test was easy was echoed by the IRT student ability analyses, which ranged from +4.20 (extremely high, for such estimates rarely go higher than +3.0) to +.15 (much higher than the typically lowest possible estimate of -3.0). The K-R21 reliability estimate was a very low .66, and the standard error of measurement was 2.82. The more liberal K-R20 reliability estimate provided by Quest 2.1 was .71, still relatively low. On the basis of these data alone, this test was not suitable for sole use in making exemption and retention decisions from the ITA workshop. Both reliability estimates were low and the standard error of measurement moderately broad.
Research question #2 . There were discrepancies in hypothetical program exemption and retention decisions between the students’ total raw score data set and the IRT student ability estimate data set. Based on the total raw score data set, an arbitrary cut point of 36 (between the 18th and 19th cases) was established (the individual error estimate at this point in the distribution was .48, reasonably low considering the error estimates ranged from 1.06 to .39). The student immediately above the cut score had a raw score of 36 and an IRT student ability estimate of 1.75. Two students with lower student ability estimates (both had 1.64) but with raw scores of 36 and 37 would have been exempted from the program, perhaps inappropriately. Three students with high student ability estimates of 2.21, 2.29, and 2.79 had raw scores of 34, 32, and 29, respectively, and would have been retained in the program, perhaps inappropriately. If one goes by the total raw scores, five out of forty students are potentially misplaced. See Table 4 below for a comparison of student total raw scores and student ability estimates: [-9-]
Table 4
Comparison of student exemptions and retentions:
Total raw scores and IRT student ability estimates
| Student ID Numbers |
Rank |
Raw Score |
IRT Student |
|
2-18 |
1 |
43 |
4.20 |
|
. |
. |
. |
. |
|
. |
. |
. |
. |
|
2-10* |
11 |
37 |
1.64 |
|
. |
. |
. |
. |
|
1-19* |
16 |
36 |
1.64 |
|
2-13 |
18 |
36 |
1.75 |
|
Hypothetical cut point (total raw score = 36, IRT student ability estimate = 1.75) |
|||
|
1.-8 |
19 |
35 |
1.43 |
|
. |
. |
. |
. |
|
1-11** |
20 |
35 |
2.21 |
|
. |
. |
. |
. |
|
. |
. |
. |
. |
|
2-7** |
24 |
32 |
2.29 |
|
1-1** |
33 |
29 |
2.79 |
|
. |
. |
. |
. |
|
. |
. |
. |
. |
|
1-7 |
40 |
24 |
.49 |
| Note: Only the highest, lowest, borderline and potentially misplaced cases are reported here. * indicates student potentially inappropriately exempted. **indicates student potentially inappropriately retained. |
|||
This result may not seem important, except when one realizes that exemption and retention decisions for the International Teaching Assistant Workshop are high stakes. If a student is wrongly exempted, he or she will be recommended to teach first-year classes. If any first-year students complain about international teaching assistants’ language abilities, the department may lose funding, according to state mandate. If a student is wrongly retained, he or she must attend three weeks of intensive teaching and language practice, and three rounds of difficult performance assessments. Students who do not “pass” the workshop may lose financial support from their departments (although they usually do not, at least for the first year). For many, this may mean the difference between staying and leaving the U.S. [-10-]
Research question #3 . The more liberal K-R20 reliability estimate for the ELILCT with this group of students was 0.71. For a commercially produced norm-referenced test, this is a low score. Norm-referenced tests that are administered to a group with relatively homogeneous abilities (as was this group) tend to have depressed reliabilities (Brown, 1996, p. 209). The item fit map indicated that three items, 12, 13, and 25, were below the threshold of 0.74 (2 times the infit mean square of .13 minus the infit mean square of 1.00; see McNamara, 1996, p. 181). This shows that students responded in significantly different ways than predicted on those three items. The three items may contribute to measurement error (and lower reliability) either because:
- the items are tapping into a different construct than the other 42 items;
- the test items are poorly constucted; or
- a technical problem prevented students’ responses from being registered on those three items.
Student case estimate outputs were examined for non-fitting cases, i.e., students who may appeared to respond randomly (perhaps due to a technical problems). There were no significant t-values for fit. The itanal (distractor analysis) report revealed potentially serious problems at the item level of the ELILCT. Table 5 below shows the percentage of students answering the item correctly, and the number of missing data points for each item. A missing data point might mean that certain students did not press their answer buttons or that certain students pressed their answer buttons but the computer did not register their responses.
Table 5
IRT itanal report (distracter efficiency analysis)
| Item | Percent of Students Answering Correctly |
Missing Data |
Item | Percent of Students Answering Correctly |
Missing Data |
Item | Percent of Students Answering Correctly |
Missing Data |
|---|---|---|---|---|---|---|---|---|
| 1 |
86.8% |
2 |
16 |
79.4% |
6 |
31 |
50.0% |
2 |
| 2 |
86.5% |
3 |
17 |
96.9% |
1 |
32 |
77.8% |
22 |
| 3 |
100.0% |
1 |
18 |
97.1% |
6 |
33 |
82.6% |
17 |
| 4 |
84.8% |
7 |
19 |
87.1% |
9 |
34 |
100.0% |
9 |
| 5 |
81.6% |
2 |
20 |
88.6% |
5 |
35 |
52.5% |
0 |
| 6 |
94.9% |
1 |
21 |
100.0% |
1 |
36 |
100.0% |
2 |
| 7 |
94.7% |
2 |
22 |
94.7% |
2 |
37 |
97.5% |
0 |
| 8 |
90.0% |
0 |
23 |
100.0% |
0 |
38 |
86.8% |
2 |
| 9 |
81.6% |
2 |
24 |
74.4% |
1 |
39 |
95.0% |
0 |
| 10 |
100.0% |
5 |
25* |
54.1% |
3 |
40 |
65.8% |
2 |
| 11 |
86.8% |
2 |
26 |
76.3% |
2 |
41 |
92.1% |
2 |
| 12* |
73.7% |
21 |
27 |
76.9% |
1 |
42 |
100.0% |
1 |
| 13* |
89.5% |
2 |
28 |
100.0% |
1 |
43 |
87.5% |
0 |
| 14 |
59.5% |
3 |
29 |
58.3% |
4 |
44 |
89.2% |
3 |
| 15 |
42.1% |
2 |
30 |
71.1% |
2 |
45 |
95.0% |
0 |
Note: * indicates items that were significantly below the item fit threshold. Percentage correct figures do not include missing data points. Therefore, only the students whose responses were registered by the computer were counted.
[-11-]
In most paper and pencil listening comprehension tests with 40 students, having one or two students not answer items is not unusual. But for this test, 16 items have three or more missing data points. This suggests either problems with the computer program registering students’ responses, or it may suggest that students did answer but the button they pressed somehow did not operate. There have been anecdotal reports from students using the consoles for class work that some of the student console buttons for “Rewind” or “Play” were “stiff” and unresponsive. Either of these possibilities would be a source of serious measurement error. Note also that 27 items were answered correctly 85% or more of the time, indicating once again that the test was rather easy for the students (at least for the ones whose responses were registered by the computer). Finally, note that one of the misfitting items, #12, had 21 missing data points. But the other two misfitting items, #13 and #25, have two and three missing data points, respectively. It is possible that items #13 and #25 are substantively different in format than the other items (upon later analysis, item 13 was found to have two possible correct answer choices), and yet an additional source of measurement error. Generally speaking, the computer mediated version of ELILCT was not reliable with this particular group of students, both for reasons related to the test alone, and for reasons associated with the computer program used to administer the test.
Research question #4 . Results of the student questionnaire (N = 40) are given below. For the item: “This was the first time for me to take a computer mediated test,” 28 out of 40 students answered “yes,” and 11 students answered “no.” For the next four items, students were asked to gauge their level of agreement with four statements. A response of “4” meant “strongly agree,” “3” meant “agree,” “2” meant “disagree,” and “1” meant “strongly disagree.” Descriptive statistics for the items are given below in Table 6.
Table 6
Descriptive statistics for items 2, 3, 4, and 5 on the student feedback questionnaire .
2. The instructions for the test were clear.
| M = 3.425 | SD = .703 | min/max = 1/4 | mode = 4 | skew = -1.243 | kurtosis = 1.669 |
3. I was able to find the correct buttons (“A,” “B,” “C”) to press after hearing each question.
| M = 3.275 | SD = .707 | min/max = 1/4 | mode = 3.0 | skew = -.872 | kurtosis = .935 |
4. I could clearly hear the questions through my headphones.
| M = 3.350 | SD = .760 | min/max = 1/4 | mode = 4.0 | skew = -1.365 | kurtosis = 2.096 |
5. I think my score on this test is probably correct.
| M = 3.050 | SD = .740 | min/max = 1/4 | mode = 3.0 | skew = -.820 | kurtosis = 1.031 |
Students in general seemed to agree that the test instructions were clear (mean=3.425, mode=4, negative skew = -1.243). Students also agreed that they could find the buttons they wished to press to respond to the test prompts (mean=3.275, negative skew = -0.872. Students agreed they could hear the test prompts through the headphones (mean=3.350, mode=4, negative skew= -1.365). However, students agreed less with the notion that the scores on the computer-mediated test were correct (mean=3.050, mode=3). Students’ responses to item 6, “Taking a computer mediated test is easier/harder than making my answers on a separate answer sheet with a pencil,” were “easier” = 16, and “harder” = 19. Five students did not respond to this item. [-12-]
In their written responses to the open-ended item asking for additional comments, 19 students responded. Students were concerned that they had no way of knowing, whether visually or aurally, whether their answers had been registered by the computer:
Some kind of display for the answers should be there on screen.
After each of the question and before the next question starts, it’s better
To have a sound such as “diiiiiiii” to alarm the begin of the next question.
Seven students made comments like the above. Eight students complained that they were unable to change their answers once they had pressed the button:
I pressed the wrong button sometime but I couldn’t correct it.
One student wanted the response buttons to be on the right side of the console, not the left. One additional student commented that he or she was not always sure which item he or she was responding to.
Results of the test proctor questionnaire (N = 5) are given in Table 7 below. For the item: “This was the first time for me to administer a computer-mediated test,” five test proctors said “yes,” and zero said “no.” For the next three items, test proctors were asked to gauge their level of agreement with four statements. A response of “4” meant “strongly agree,” “3” meant “agree,” “2” meant “disagree,” and “1” meant “strongly disagree.”
Table 7
Descriptive statistics for items 2, 3, and 4 on the test proctor feedback questionnaire.
2. The instructions for the test were clear.
| M = 3.6 | SD = .548 | min/max = 3/4 | mode = 4 | skew = -.408 | kurtosis = -1.833 |
3. I thought students were generally able to find the correct buttons (“A,” “B,” “C”) to press after hearing each question.
| M = 3.2 | SD = .447 | min/max = 3/4 | mode = 3 | skew = 1.5 | kurtosis = .250 |
4. I think students’ scores on this test is probably accurate.
| M = 3.00 | SD = 0 | min/max = 3/3 | mode = 3 | skew = 0 | kurtosis = 0 |
Note: Standard deviation formula N – 1 used.
Test proctors’ responses generally mirrored students’ levels of agreement. They agreed that the test instructions were clear (mean=3.6, mode=4). They felt less agreement that students were able to find the correct response buttons to press (mean=3.2, mode=3). They agreed still less with the statement that students’ scores on the test were correct (mean=3.0, mode=3). It should be noted, however, that no students’ or proctors’ responses ever went below the level of 3, meaning a level of basic agreement with all of the statements. [-13-]
Test proctors’ responses to the open-ended question: “What problems came up?” revealed technical problems with the computer examination program. One test proctor reported that students were concerned that they could not change their answers once they had pressed a response button. Another test proctor thought that while some items had 12 seconds between them, others did not. In a related comment, a test proctor noted that students had told him the “time tracker” on each student console (a digital display indicating how much time they had left to respond to the item) was not consistent. A final test proctor noted that students were concerned they could not determine whether the computer had registered their response, nor could they see what response the computer had registered after they had pressed their response button. In other words, if they had pressed “B,” they had no visual signal on the console to confirm that was the response the computer registered.
Discussion
The ELILCT was not suitable for use in making program exemption and retention decisions for participants in the Summer 2000 International Teaching Assistant Workshop at Texas Tech University. The reasons can be grouped into two general categories: problems having to do with the ELILCT, and problems having to do with the computer-mediated test administration.
Problems having to do with the ELILCT . The total raw score descriptive data (Table 3) and the IRT itanal report (Table 5) indicated that students’ scores were high, and that many items on the test were too easy for them. The test was not able to estimate students’ listening comprehension abilities above a certain general level of ability. The test was a blunt instrument, and offered little information about this particular group of students’ listening comprehension abilities. It could be argued that “if the students are getting most of the test questions right, then their listening comprehension abilities are good. That’s enough for me.” However, this begs the question of what is “good.” Students getting most of the items correct on the ELILCT simply means they have hit an artificial ceiling imposed by the writers of the test. ELILCT writers did not write more difficult items for the test, and even admitted in a quotation provided above that the ELILCT items seemed easier for their norming group than items on the other grammar, vocabulary, and reading components of the Michigan Test.
This also begs the question of what this “good” level on the ELILCT actually means in terms of ITAs’ abilities to use their listening comprehension skills in their roles as teachers of undergraduate students. For instance, there is no demonstrated connection between the skills needed to get a high score on the ELILCT, which uses slow, Midwestern dialect for the item prompts, and the skills needed to comprehend West Texas first-year students’ questions, as our international teaching assistants must do.
Comprehension of students’ questions is a very different task than answering multiple choice “aural grammar” questions. Further, the test makers themselves admit: “it [the test] does not involve questions which require the processing of long discourse, nor does it provide students with redundancies and additional contextual information as would occur in expanded discourse” (ELI, 1986, p. 1). There is a clear mismatch between the situations in which listening skills are demanded of ITAs, and the ELILCT test-taking situation.
Further, this is not a good situation when one wants to make high-stakes program exemption or retention decisions. Norm-referenced tests, such as the ELILCT, are designed to spread students out along a wide continuum of skills. The broader the continuum, the lower the standard error of measurement and IRT individual error estimates, the more confidently testers can make cut scores. When students’ scores are clustered at the high end of the continuum, cut scores cannot be made with much confidence. Students clustered around the cut score could take the test again, and score higher or lower than the cut score simply by chance.
Finally, the item fit map indicated that two items (#13 and #25, and potentially #12) were misfitting, suggesting that the two items were perhaps measuring a different trait than the other items in the test. A lot has been learned about the nature of listening comprehension and about human trait measurement since 1972, when the ELILCT was written. A more optimal test would incorporate these advances in knowledge.
Problems having to do with the computer-mediated version of the ELILCT . On the one hand, the computer mediated version of the ELILCT allowed for timely and necessary analysis of students’ responses. On the other hand, the data analyses (in particular, see Table 5) indicated that on some items, unusually large numbers of students were not responding. Given students’ overall high abilities in relation to the test, it seems unlikely that students responded incorrectly to these items. Rather, it is more likely that they pressed the answer buttons and the computer examination program did not register their responses. This may be due to problems with the buttons themselves or with the software, which may not have consistently allowed a full 12 seconds after each item for students’ responses to be registered. [-14-]
Further investigation of this assumed 12 twelve second gap was conducted. The tape was played and the pauses in seconds were measured between each with two raters using two stopwatches (there was a high degree of agreement between the two raters). While 16 items were separated by 12 seconds of silence, 14 items were separated by 11, 10 or 9 seconds, and 15 items were separated by 13, 14, or 16 seconds. This surely generated measurement error.
Students’ written comments suggest that their anxieties about taking a computer-mediated test would be greatly lessened if they knew whether their responses were being registered by the computer. Registration of a student response could be acknowledged by an audio tone or a visual signal on the console displays.
The importance of multiple sources of data for making appropriate decisions . Readers will be relieved to know that workshop staff did not rely on the ELILCT scores to make exemption and retention decisions for the workshop. Given the results reported in this study, using the ELILCT scores would have led to demonstrably inappropriate decisions.
Pairs of workshop staff also conducted individual interviews with students, which included warm-up questions, oral reading of scientific passages by students, and then short presentations of a scientific term in their field. Finally, students responded to questions the staff had about the presentation. The following day, all workshop staff reviewed the two rating and comment sheets for each student (one for each rater) and made exemption and retention decisions by consensus. As the interviews tapped into very different constructs and skills (fluency, pronunciation, and the ability to comprehend and respond appropriately to questions, among other things) than measured by the ELILCT (an “aural grammar” test), students’ rankings according to their IRT student ability estimates on the ELILCT had little relationship with the staff’s workshop exemption and retention decisions. Twelve students with IRT student ability estimates of over 1.75 who, if only the ELILCT results had been used, would have been exempted from the program, were retained in the program on the basis of their performances in their individual interviews. Two students with IRT student ability estimates below 1.75, who would have been retained in the workshop on the basis of their ELILCT scores alone, were exempted from the workshop on the basis of their individual interviews. It seems likely that the ITA Summer Workshop will be seeking another, more appropriate source of data on students’ listening comprehension abilities.
Conclusion
This report recounted the administration of a computer-mediated version of the Michigan Listening Comprehension Test (ELILCT). The test was administered in this form because it was necessary to have the item-level data to analyze and then determine whether the ITA Summer Workshop staff could make appropriate decisions using the test results. For reasons relating to both the ELILCT and the computer-mediated version of this test, the test data could not be used for making program exemption and retention decisions. This report also demonstrated the use of an array of classical total raw score analyses and IRT analysis for test results to make decisions, and to pinpoint problematic items that may have been due to test design problems or test administration problems. Clearly, test results used to make decisions about students’ lives must be analyzed beyond the point of calculating total raw scores, setting a cut score, and then making decisions based on that cut score.
Note
[1]Unfortunately, participants’ TOEFL subtest scores, particularly on the listening subtest, were not available at the time of this report. [-15-]
References
Adams, R.J. & Khoo, S.T. (1996). Quest 2.1 (computer software). Victoria, Australia: The Australia Council for Educational Research.
ASC 4.2 DI8 Multi Media Centre [Computer software]. (1996). Hösbach, Germany: ASC Telecom.
Brown, J.D. (1996). Testing in language programs. Upper Saddle River, NJ: Prentice Hall Regents.
English Language Institute (1986). English language institute listening comprehension test manual. Ann Arbor, MI: Author.
Hambleton, R.K. Swaminathan, H., & Rogers, H.J. (1991). Fundamentals of item response theory. Newbury Park, CA: Sage.
McNamara, T. (1996). Measuring second language performance. Harlow, Essex (U.K.): Addison Wesley Longman Limited.
Statview 4.5 (Computer software). (1995). Berkeley, CA: Abacus Concepts.
Testing and Certification Division (1972). English language institute listening comprehension test. Ann Arbor, MI: Author.
About the authors
Greta Gorsuch is Assistant Professor of Applied Linguistics and Director of International Teaching Assistant Training at Texas Tech University. Her interests focus on teacher learning and development in ESL and EFL contexts, and language testing practices.
Tom R. Cox is a degree candidate in the M.A. program in Applied Linguistics, at Texas Tech University. His research interests include testing of interpreters working between English and American Sign Language.
|
© Copyright rests with authors. Please cite TESL-EJ appropriately. Editor’s Note: Dashed numbers in square brackets indicate the end of each page for purposes of citation. |
[-16-]